How to investigate the indexing time of custom fields in Jira Data Center installation?
In that article, I would like to share the usage of new functionality from 8.10 Jira DC in the cluster monitoring tab and say thank you to the Atlassian development team. Because previous we do parsing logs, check indexes via Luke, and do testing via benchmark tools.
As we know many recommendation around custom fields creation:
- Government (documentation and do more generic etc)
- Context configurying (https://confluence.atlassian.com/adminjiraserver/custom-fields-with-global-contexts-956713282.html)
- Standard indexers vs custom indexers
- Periodically do a cleanup (with custom app, with built-in functionality)
- Custom field optimizer
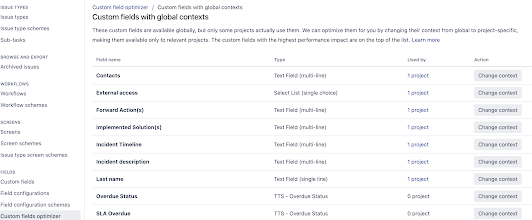
But one problem is unclear, when we need to start to investigate a problem, why is SysOps annoying if we want to add new custom fields, how to measure?
So Atlassian enrolled in 8.10.x the UI and released a feature with the name the more insights for custom fields. It’s part of feature Indexing Stats - cost of indexing custom fields which works for the Server and DC release from 8.1.x (https://confluence.atlassian.com/jirakb/indexing-stats-cost-of-indexing-custom-fields-1002473438.html).
If you are on a DC release, I hope you’re already on it.
Let’s review the feature:
- We had a jira base url https://jirasandbox.example.com for sandbox with 3 mln issues, 1.5k custom fields as an anonymized copy of production system.
- After https://jirasandbox.example.com/plugins/servlet/cluster-monitoring
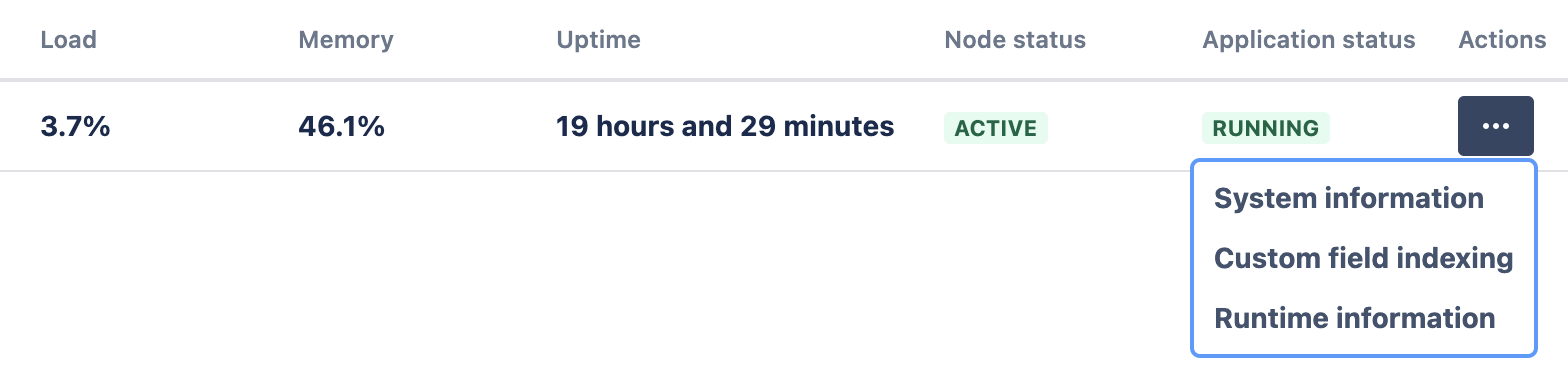
- In tab custom field indexing,

As a result we can find the 10 Total and 10 Snapshot time consuming fields.
Also, I am really happy with that feature which can be exported and do analysis, and do cleanup based on that info.
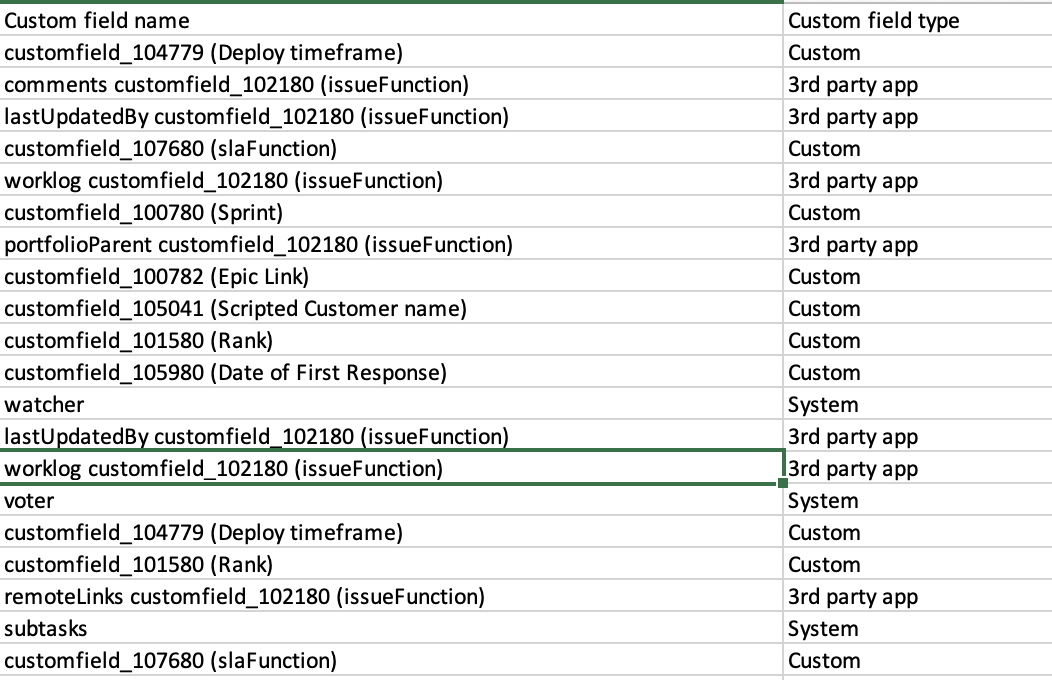
Conclusion:
Based on that info I will review the top time consuming the fields.
Review a few system fields
Check issueFunction from Adaptavist Scriptrunner
Check a few calculated custom fields
Please, be aware that top time consuming fields are related to the one of test installation. Please, do an investigation on your instance before making a conclusion.
References:



Comments
Post a Comment