How to migrate custom field values with groovy or not?

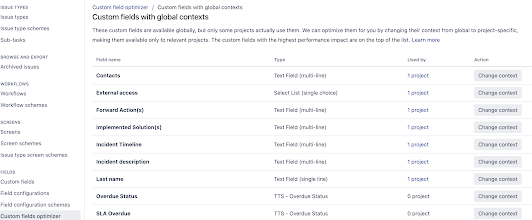
Hi! Today I would like to share a possible way to migrate or merge a custom field during a periodical cleanup. Possible ways are built-in functionality of Scriptrunner or myGroovy, own code and own yet another alternative way for the complicated situation. Also,you can follow with next typical steps of cleanup process: Detect the fields Create a ticket about merge plan Detect the JQL, agile boards queries via database queries in tables searchrequest, add info into ticket Prepare the optimized the context in the comment of ticket Notify project stakeholders in the Jira ticket Get approvals Inform via slack (email) the next merge the end users affected for that changes Execute the action. This is my typical process for the cleanup activity. As an example , let’s do the next real case with screenshots. Goal: Migrate from the Production environment field to Products field. Both fields are pickers. Where some of ...